Технический форум по робототехнике.
Правила форума
В этом форуме новые темы не создаются, однако обсуждение допустимо.
EDV » 11 май 2011, 19:20
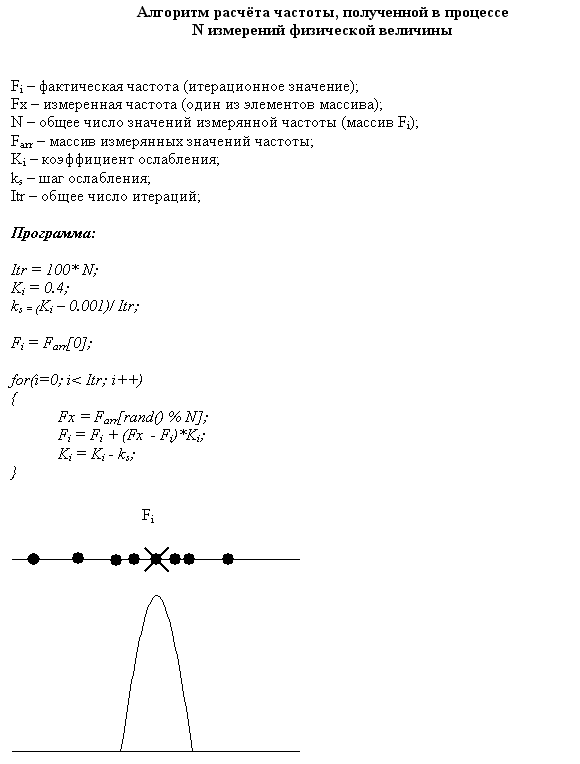
Это частный случай карты Кохонена, в которой только один «нейрон». В начале этот нейрон (Fi) будет сильно изменять своё значение, подстраиваясь под значения выборки (Fx), но чем ближе к концу обучения, тем меньше будет Fi изменяться, так как воздействие на него с течением времени будет ослабляться коэффициентом Ki. В результате значение Fi окажется в точке, вокруг которой «роятся» значения выборки Fx, то есть в «кластере».
Чем это отличается от усреднения (математического ожидания)?
Да тем, что если в усредняемой выборке попадётся «скачёк», значение которого будет сильно отличаться от значения «кластера», то при усреднении этот скачёк уведёт в сторону усреднённое значение от фактического «кластерного» значения параметра.
=DeaD= » 11 май 2011, 19:29
Так этот скачек и так и так уведет значение в сторону. Просто попробуй проверить на среднее по матожиданию
 Добавлено спустя 58 секунд:
Добавлено спустя 58 секунд:Ибо этот скачек в среднем тут попадётся те же 100 раз в среднем и так же всё в его сторону уплывёт.
Michael_K » 11 май 2011, 19:31
Честно, не вижу оснований для такого вывода.
Скачок усреднится ровно так же, как и любое другое значение - в среднем с ровно тем же весом.
Добавлено спустя 18 секунд:
Dead апиридил.
EDV » 11 май 2011, 19:41
=DeaD= писал(а):Ибо этот скачек в среднем тут попадётся те же 100 раз в среднем и так же всё в его сторону уплывёт.
Вот только отклонение от текущего значения берётся не целиком а только его часть (Fx – Fi)*Ki, которая ещё и уменьшается с течением времени, и соответственно эта часть (если она не повторяется слишком часто) не может в общей массе существенно повлиять на конечный результат.
Нет, при таком алгоритме как бы «голосует» большинство, и одиночные «скачки» будут просто проигнорированы (вот если бы их побольше было бы, тогда повлияло бы на конечный результат существенно).
=DeaD= » 11 май 2011, 19:48
Ровно так же как и при усреднении.
Just try!
(просто попробуй реально выдать среднее и этот алгоритм что выдаст в среднем при N-кратном запуске на перетусованном массиве измерений и найти 10 отличий)
Добавлено спустя 5 минут 10 секунд:Игнорирование скачков выполняется классически отсеканием какого-то % значений отклоняющихся более всего от среднего. Два простейших подхода:
1. Медиана;
2. Выкидываем 5% минимальных и 5% максимальных, затем ищем среднее;
Очевидно медиана, это когда выкинули 49.999% минимальных и 49.999% максимальных, осталось 0.002% посредине

EDV » 11 май 2011, 23:23
Попробовал сделать несколько экспериментов на искусственно сгенерированных выборках данных, и получилось что результаты работы «кластерного» алгоритма близки к среднему значению, и одиночные «скачки» на него влияют.
Однако на практике «кластерный» алгоритм, почему-то даёт лучшие результаты, чем просто усреднение. Возможно, закон распределения случайной величины в искусственно сгенерированной выборке отличается от закона распределения выборки полученной при измерении реального параметра, и у этого алгоритма на выходе действительно получается значение стоящее ближе к фактическому значению измеряемого параметра, чем просто усреднённое значение выборки. В общем, тут нужно тестировать и сравнивать на реальных данных (таблицы, графики и т.д.).
=DeaD= » 12 май 2011, 07:46
Я бы сказал так - на среднее значение глюк повлияет гарантированно и известно как, а на этот подход среднее значение влияет с некоторым случайным весом. Т.е. если хочешь получить то же самое, но вычислительно дешевле - возьми не арифметическое среднее, а вероятностное среднее, которое вычисляется как Fx=(S1*F1+S2*F2+...+Sn*Fn)/(S1+S2+...Sn), где Fi это измерения, а Si это случайные величины от 1 до 100 с равномерным распределением.
EDV » 12 май 2011, 08:49
Можно будет попробовать, возможно, действительно на результат, в лучшую сторону, влияет именно случайная составляющая в цикле расчёта параметра по выборке.
Ну, как бы ни было, но этот метод хорошо работает на практике. Так что побольше бы таких «случайностей»
Виталий » 12 май 2011, 13:22
Однако на практике «кластерный» алгоритм, почему-то даёт лучшие результаты, чем просто усреднение.
Даже и не знаю. Я бы назвал этот алгоритм рандомизированным.
Это правда в реальном случае и неправда в предельном.
Если массив достаточно большой, то результаты будут почти неотличимы, а если массив маленький, то рандомизированный алгоритм в среднем будет давать лучшую оценку, т.к. будет игнорировать выбросы.
Самый известный из таких алгоритмов - RANSAC.
=DeaD= » 12 май 2011, 14:53
Виталий писал(а):Если массив достаточно большой, то результаты будут почти неотличимы, а если массив маленький, то рандомизированный алгоритм в среднем будет давать лучшую оценку, т.к. будет игнорировать выбросы.
Смотря что считать этим "в среднем". Я всё еще считаю, что в смысле матожидания он "в среднем" будет давать ровно арифметическое среднее.
EDV » 12 май 2011, 17:56
О сколько нам открытий чудных
Готовят просвещенья дух
И опыт, сын ошибок трудных,
И гений, парадоксов друг,
И случай, бог изобретатель...
Уж чего-чего, а удачных «случайностей» при разработке AVM было предостаточно...
Иногда сам удивляюсь

Michael_K » 12 май 2011, 20:18
Виталий писал(а):Даже и не знаю. Я бы назвал этот алгоритм рандомизированным.
Это правда в реальном случае и неправда в предельном.
Если массив достаточно большой, то результаты будут почти неотличимы, а если массив маленький, то рандомизированный алгоритм в среднем будет давать лучшую оценку, т.к. будет игнорировать выбросы.
А ничего, что там количество выборок даже из небольшого массива в сто раз превышает количество данных в массиве? То есть, как ни крути, усреднение будет хорошим (конечно если ранд() не сильно кривой).
Виталий писал(а):Самый известный из таких алгоритмов - RANSAC.
Это же совсем другое! Там есть порог отсечения "неудачных" точек, критерии оценки "удачности". А тут нет - тупо все подряд складываются и все. Случайность здесь только шум вносит. С таким же успехом можно тупо усреднить и добавить случайную величину смасштабированную на СКО.
Вообще в данном случае, медиана, наверное, работала бы неплохо.
Добавлено спустя 1 минуту 40 секунд:EDV писал(а):Уж чего-чего, а удачных «случайностей» при разработке AVM было предостаточно... Иногда сам удивляюсь
Эмпирика эмпирикой, но как-то анализировать же нужно...
Ну для оптимизации хотя бы. Вы же за ФПС боретесь в конце-то концов.
EDV » 12 май 2011, 20:58
Слушайте, то что мы все пока что не можем понять как алгоритм умудряется фильтровать зашумлённые данные, тем не менее, не мешает алгоритму успешно находить (фильтровать) координаты местоположения

Хотя, конечно, наверняка существуют методы фильтрации и получше
Michael_K » 12 май 2011, 21:10
Я думаю, что вас просто спасает то, что вы получаете случайные отклонения, но достаточно часто, таким образом можно снизить погрешности "дискретизации", к примеру. То есть у вас сам алгоритм ищет картинки неточно, причем систематически неточно (распределение погрешностей не нормальное). А вы за счет случайных отклонений получаете более равномерно распределенный "шум".
Но вообще, я бы избегал таких "алгоритмов".
EDV » 12 май 2011, 21:18
Там не просто «картинки» там каждому распознанному маркеру (маяку) ставятся в соответствие (ассоциируются) координаты местоположения (и некоторые из них могут быть совсем «не из той оперы»). То есть робот видит набор «картинок» за которым закреплён набор «координат» и вот из такого набора нужно вычислить текущее местоположение.