2EDV: Ну вроде первый этап пройден, платформу адаптировали, алгоритм на другой платформе проверили, куда дальше двинемся? Может попробовать доделать алгоритм распознавания, чтобы он точно координаты образа определял? А то без этого локализация будет с очень малой точность мне кажется (+\- 10см) и SLAM наверное тяжело будет применять.
Хотя можно распараллелить задачи или даже вообще сначала сделать SLAM с плохой точностью распознавания и потом заняться ею.
Сейчас посмотрю что есть из готового для SLAM'а.
| |
roboforum.ruТехнический форум по робототехнике. |
|
Использование Navigator Tool Kit
Сообщений: 66
• Страница 4 из 5 • 1, 2, 3, 4, 5
Re: Использование Navigator Tool Kit
![]() =DeaD= » 24 окт 2009, 20:48
=DeaD= » 24 окт 2009, 20:48
-

=DeaD= - Сообщения: 24218
- Зарегистрирован: 06 окт 2004, 18:01
- Откуда: Ебург
- прог. языки: C++ / PHP / 1C
- ФИО: Антон Ботов
Re: Использование Navigator Tool Kit
![]() EDV » 26 окт 2009, 10:00
EDV » 26 окт 2009, 10:00
>> Ну вроде первый этап пройден, платформу адаптировали, алгоритм на другой платформе проверили,
куда дальше двинемся? Может попробовать доделать алгоритм распознавания, чтобы он точно координаты образа определял?
2=DeaD=:
Точность распознавания алгоритма AVM в будущем, конечно, планируется улучшать, но это всё будет выполняться на фоне разработки алгоритмов навигации. А пока будем использовать возможности текущей версии алгоритма AVM.
Для начала, просто попробуй поэкспериментировать с исходными текстами библиотек навигации (любые эксперименты), ну просто что бы освоиться и возможно придумать пару тройку новых идей, на тему: «Как построить алгоритм навигации?»
Я пока что подготовлю и выложу новые наработки по «Navigator tool kit» (постараюсь в течение недели).
Ещё раз хочу обратить внимание на тот факт, что значение «ключевого размера» изображения очень важен для алгоритма AVM. Во первых, AVM начинает поиск объектов, сканируя входное изображение окном, начальный размер которого составляет 75% от ключевого размера (то есть всё что меньше, AVM найти не сможет). Во вторых, от ключевого размера зависит количество коэффициентов в матрицах распознавания и количество уровней дерева поиска (чем больше ключ, тем более детальные матрицы и большее количество уровней участвует в декомпозиции, и тут важно не перестараться). Так же прошу не путать «ключевой размер» (который необходим для создания нового экземпляра AVM, то есть инициализации) с «областью интереса», которая используется для обучения AVM на новый объект. После того как ключевой размер задан, можно обучать AVM (изменяя размеры области интереса) на объекты, размер которых может быть больше чем ключевой размер (см. пример «Face training demo»). Выбор ключа 80x80 пикселей – оптимален для AVM в большинстве случаев.
куда дальше двинемся? Может попробовать доделать алгоритм распознавания, чтобы он точно координаты образа определял?
2=DeaD=:
Точность распознавания алгоритма AVM в будущем, конечно, планируется улучшать, но это всё будет выполняться на фоне разработки алгоритмов навигации. А пока будем использовать возможности текущей версии алгоритма AVM.
Для начала, просто попробуй поэкспериментировать с исходными текстами библиотек навигации (любые эксперименты), ну просто что бы освоиться и возможно придумать пару тройку новых идей, на тему: «Как построить алгоритм навигации?»
Я пока что подготовлю и выложу новые наработки по «Navigator tool kit» (постараюсь в течение недели).
Ещё раз хочу обратить внимание на тот факт, что значение «ключевого размера» изображения очень важен для алгоритма AVM. Во первых, AVM начинает поиск объектов, сканируя входное изображение окном, начальный размер которого составляет 75% от ключевого размера (то есть всё что меньше, AVM найти не сможет). Во вторых, от ключевого размера зависит количество коэффициентов в матрицах распознавания и количество уровней дерева поиска (чем больше ключ, тем более детальные матрицы и большее количество уровней участвует в декомпозиции, и тут важно не перестараться). Так же прошу не путать «ключевой размер» (который необходим для создания нового экземпляра AVM, то есть инициализации) с «областью интереса», которая используется для обучения AVM на новый объект. После того как ключевой размер задан, можно обучать AVM (изменяя размеры области интереса) на объекты, размер которых может быть больше чем ключевой размер (см. пример «Face training demo»). Выбор ключа 80x80 пикселей – оптимален для AVM в большинстве случаев.
-

EDV - Сообщения: 1016
- Зарегистрирован: 06 июн 2007, 15:19
- Откуда: Украина, Лисичанск
- ФИО: Дмитрий Еремеев
Re: Использование Navigator Tool Kit
![]() =DeaD= » 26 окт 2009, 11:00
=DeaD= » 26 окт 2009, 11:00
Про поиграться - окей, понял, сегодня помодифицирую уже 
А в какую сторону новые наработки?
А в какую сторону новые наработки?
-
=DeaD= - Сообщения: 24218
- Зарегистрирован: 06 окт 2004, 18:01
- Откуда: Ебург
- прог. языки: C++ / PHP / 1C
- ФИО: Антон Ботов
Re: Использование Navigator Tool Kit
![]() EDV » 26 окт 2009, 11:47
EDV » 26 окт 2009, 11:47
Ну, идея всё та же: есть две точки – точка, где мы находимся в текущий момент (положение камеры) и точка, куда мы можем отправиться (M1, Mc, M2).
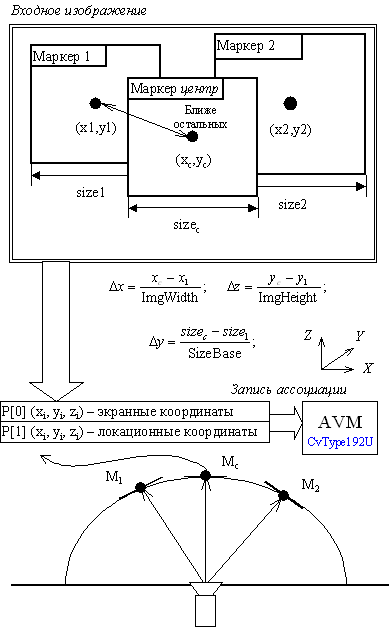
Идея: Использовать для определения первой и второй точек только алгоритма AVM.
В начале, для определения текущего местоположения я хотел использовать алгоритм «Классификации контрастных пятен» (ККП), но на практике он работает гораздо хуже, чем AVM.
Идея: Использовать для определения первой и второй точек только алгоритма AVM.
В начале, для определения текущего местоположения я хотел использовать алгоритм «Классификации контрастных пятен» (ККП), но на практике он работает гораздо хуже, чем AVM.
-
EDV - Сообщения: 1016
- Зарегистрирован: 06 июн 2007, 15:19
- Откуда: Украина, Лисичанск
- ФИО: Дмитрий Еремеев
Re: Использование Navigator Tool Kit
![]() =DeaD= » 26 окт 2009, 11:50
=DeaD= » 26 окт 2009, 11:50
Не понял не то что идею, а даже - к чему она? Какую задачу решаем?
-
=DeaD= - Сообщения: 24218
- Зарегистрирован: 06 окт 2004, 18:01
- Откуда: Ебург
- прог. языки: C++ / PHP / 1C
- ФИО: Антон Ботов
Re: Использование Navigator Tool Kit
![]() EDV » 26 окт 2009, 16:01
EDV » 26 окт 2009, 16:01
Давай попробую объяснить, только в другой теме: «Автономная навигация робота»
-
EDV - Сообщения: 1016
- Зарегистрирован: 06 июн 2007, 15:19
- Откуда: Украина, Лисичанск
- ФИО: Дмитрий Еремеев
Re: Использование Navigator Tool Kit
![]() EDV » 10 ноя 2009, 17:27
EDV » 10 ноя 2009, 17:27
Я подправил библиотеку распознавания. Теперь стало работать гораздо шустрее на разрешении 640x480.
Обновил программные пакеты:
http://edv-detail.narod.ru/AVM_SDK_v0-5.zip
http://edv-detail.narod.ru/Navigator_src.zip
http://edv-detail.narod.ru/Navigator_Tool_Kit.zip
Обновил программные пакеты:
http://edv-detail.narod.ru/AVM_SDK_v0-5.zip
http://edv-detail.narod.ru/Navigator_src.zip
http://edv-detail.narod.ru/Navigator_Tool_Kit.zip
-
EDV - Сообщения: 1016
- Зарегистрирован: 06 июн 2007, 15:19
- Откуда: Украина, Лисичанск
- ФИО: Дмитрий Еремеев
-
=DeaD= - Сообщения: 24218
- Зарегистрирован: 06 окт 2004, 18:01
- Откуда: Ебург
- прог. языки: C++ / PHP / 1C
- ФИО: Антон Ботов
Re: Использование Navigator Tool Kit
![]() EDV » 10 ноя 2009, 17:47
EDV » 10 ноя 2009, 17:47
Нет, ещё не смотрел MSRS, так проинсталлировал, но как пользоваться, пока не разобрался.
Ну а у тебя как успехи?
В принципе, всё что нужно по нашей теме – это управление роботом (программный интерфейс от нашего модуля "Navigator") и захват изображения из «глаз» робота (обратно в наш модуль).
В эмуляторе MSRS есть такая возможность?
Ну а у тебя как успехи?
В принципе, всё что нужно по нашей теме – это управление роботом (программный интерфейс от нашего модуля "Navigator") и захват изображения из «глаз» робота (обратно в наш модуль).
В эмуляторе MSRS есть такая возможность?
-
EDV - Сообщения: 1016
- Зарегистрирован: 06 июн 2007, 15:19
- Откуда: Украина, Лисичанск
- ФИО: Дмитрий Еремеев
Re: Использование Navigator Tool Kit
![]() =DeaD= » 10 ноя 2009, 22:40
=DeaD= » 10 ноя 2009, 22:40
В эмуляторе MSRS это есть, но пока осваиваю как что там прикручивать надо получается пока так себе, так как я в .NET новичок вообще 
Да и времени толком не получается выделить на эту задачу, всё отрывками сажусь обычно, когда концентрация уже так себе, но в эти выходные вроде пока ничего не запланировано, так что надеюсь продвинусь.
Пока разобрался, что и как в целом работает там, сейчас буду конкретику изучать и пробовать все это покрутить руками.
Добавлено спустя 2 часа 46 минут 18 секунд:
Выложу тут ролик в исходном качестве с тестовым заездом - попросили посмотреть какое качество будет.
получается пока так себе, так как я в .NET новичок вообще Да и времени толком не получается выделить на эту задачу, всё отрывками сажусь обычно, когда концентрация уже так себе, но в эти выходные вроде пока ничего не запланировано, так что надеюсь продвинусь.
Пока разобрался, что и как в целом работает там, сейчас буду конкретику изучать и пробовать все это покрутить руками.
Добавлено спустя 2 часа 46 минут 18 секунд:
Выложу тут ролик в исходном качестве с тестовым заездом - попросили посмотреть какое качество будет.
- Вложения
-
 avm_demo.zip
avm_demo.zip- (4.39 МиБ) Скачиваний: 17
-
=DeaD= - Сообщения: 24218
- Зарегистрирован: 06 окт 2004, 18:01
- Откуда: Ебург
- прог. языки: C++ / PHP / 1C
- ФИО: Антон Ботов
Re: Использование Navigator Tool Kit
![]() Security Tech Lviv » 11 ноя 2009, 00:19
Security Tech Lviv » 11 ноя 2009, 00:19
А теперь вопрос. Моя програма управления роботом написана на VB6. А ваш пример на Visual C++. И как мне при етом передать команду с програмы разпознавания в программу управления если ето уже другой процес скомпилированый на другом языке?
-

Security Tech Lviv - Сообщения: 20
- Зарегистрирован: 09 май 2009, 20:56
- Откуда: Львов
Re: Использование Navigator Tool Kit
![]() EDV » 11 ноя 2009, 10:24
EDV » 11 ноя 2009, 10:24
Если ваша «программа управления, которая на VB6» управляет вашим роботом с настольного PC (то есть и наш «Navigator» и ваша «программа управления» находятся на одном компьютере), тогда достаточно открыть в вашей программе общую секцию памяти, через которую идёт обмен командами роботу от программы распознавания, и передать эти команды на ваш робот.
В C++ это выглядит следующим образом (подозреваю что в VB6 тоже есть такие функции Win32 API):
Ну а если ваша программ управления, написанная на VB6, прошита в МК вашего робота, и с вашим роботом есть связь по COM порту (радиоканал). Тогда можно взять в качестве примера исходные тексты «драйвера управления роботом» (RobotController_s1.zip) и переделать их таким образом, что бы на ваш робот по COM порту посылались команды, которые может принять и обработать ваша управляющая программа на MK робота.
В C++ это выглядит следующим образом (подозреваю что в VB6 тоже есть такие функции Win32 API):
- Код: Выделить всё • Развернуть
TKeyArray* gpKeyArray;
HANDLE mhCmdExchangeSection;
// Инициализация секций обмена командами робота
mhCmdExchangeSection = CreateFileMapping(INVALID_HANDLE_VALUE,
NULL, PAGE_READWRITE, 0, sizeof(TKeyArray), _T("RobotCmdExchange"));
gpKeyArray = (TKeyArray*) MapViewOfFile(mhCmdExchangeSection,FILE_MAP_ALL_ACCESS,0,0,sizeof(TKeyArray));
memset(gpKeyArray, 0, sizeof(TKeyArray));
...
// Коды команд робота
enum {
cmLEFT = 0, // Влево
cmBACKWARDS, // Назад
cmFORWARD, // Вперёд
cmRIGHT, // Вправо
cmTURRET_RIGHT, // Башня вправо
cmFIRE, // Залп
cmTURRET_LEFT, // Башня влево
cmPOWER // Включить/выключить питание
};
for(int i=0; i<cKeyTotal; i++) {
if(gpKeyArray->Key[i]) {
switch(i) {
case cmFORWARD:
break;
case cmBACKWARDS:
break;
case cmTURRET_LEFT:
break;
case cmTURRET_RIGHT:
break;
case cmFIRE:
break;
case cmPOWER:
break;
}
}
}
...
// Деинициализация секций обмена командами робота
UnmapViewOfFile(gpKeyArray);
CloseHandle(mhCmdExchangeSection);
Ну а если ваша программ управления, написанная на VB6, прошита в МК вашего робота, и с вашим роботом есть связь по COM порту (радиоканал). Тогда можно взять в качестве примера исходные тексты «драйвера управления роботом» (RobotController_s1.zip) и переделать их таким образом, что бы на ваш робот по COM порту посылались команды, которые может принять и обработать ваша управляющая программа на MK робота.
-
EDV - Сообщения: 1016
- Зарегистрирован: 06 июн 2007, 15:19
- Откуда: Украина, Лисичанск
- ФИО: Дмитрий Еремеев
Re: Использование Navigator Tool Kit
![]() demoontz » 11 ноя 2009, 17:57
demoontz » 11 ноя 2009, 17:57
интересно, сколько ресурсов требует программа?
я это к чему, комп конечно хорошо, но если бы можно было эту программу встроить в кпк, было бы классно!
т.е. портировать по виндовс мобайл...
я это к чему, комп конечно хорошо, но если бы можно было эту программу встроить в кпк, было бы классно!
т.е. портировать по виндовс мобайл...
- demoontz
- Сообщения: 194
- Зарегистрирован: 04 фев 2009, 20:06
- Откуда: Kiev
- Skype: demoontz
Re: Использование Navigator Tool Kit
![]() =DeaD= » 11 ноя 2009, 21:01
=DeaD= » 11 ноя 2009, 21:01
MSRS вроде есть под выньмобайл, только уже не в бесплатной версии. Ну и производительность там думаю не на высоте будет...
-
=DeaD= - Сообщения: 24218
- Зарегистрирован: 06 окт 2004, 18:01
- Откуда: Ебург
- прог. языки: C++ / PHP / 1C
- ФИО: Антон Ботов
Re: Использование Navigator Tool Kit
![]() elm » 22 ноя 2010, 13:46
elm » 22 ноя 2010, 13:46
здрасте)
вот, попытался скомпилить, удалось не с первого раза) но хотя бы удалось
но увы приложение вываливается с есепшном
а вот и собсна он
Необработанное исключение в "0x004b5548" в "Recognition.exe": 0xC0000005: Нарушение прав доступа при чтении "0xbaadf032".
вот, попытался скомпилить, удалось не с первого раза) но хотя бы удалось
но увы приложение вываливается с есепшном
- Код: Выделить всё • Развернуть
---------------------------
OpenCV GUI Error Handler
---------------------------
Sizes of input arguments do not match (Size of input data do not match to actual settings)
in function CvAssociativeMemory::ReadPackedData, d:\edv\3dvision.prj\avm_prj_rcgmxclst\src\recognitionlib_ver0.5\AssociativeMemory.h(2614)
Press "Abort" to terminate application.
Press "Retry" to debug (if the app is running under debugger).
Press "Ignore" to continue (this is not safe).
---------------------------
Прервать Повтор Пропустить
---------------------------
а вот и собсна он
Необработанное исключение в "0x004b5548" в "Recognition.exe": 0xC0000005: Нарушение прав доступа при чтении "0xbaadf032".
- elm
- Сообщения: 1
- Зарегистрирован: 22 ноя 2010, 11:52
Сообщений: 66
• Страница 4 из 5 • 1, 2, 3, 4, 5
Кто сейчас на конференции
Сейчас этот форум просматривают: нет зарегистрированных пользователей и гости: 0